Why QA is Critical for Machine Learning Models
Machine learning (ML) can be defined as a subset of Artificial Intelligence (AI) providing computer systems the ability to automatically learn from data provided to perform specific tasks. This eliminates the need of providing explicit instructions for the systems to function on a regular basis.
Traditional ML methodology has focused more on the model development process. This involved selecting the most appropriate algorithm for a given problem. In contrast, the software development process focuses on both development and testing of the software.
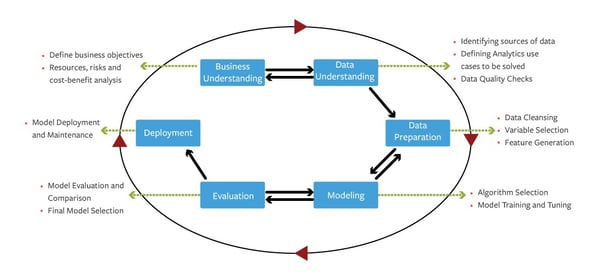
1: Cross Industry Standard Process for Data Mining (CRISP-DM)
Click to Enlarge
Testing in relation to ML model development focuses more on the model’s performance in terms of its accuracy. This activity is generally carried out by the data scientist developing the model. These models have significant real-world implications as they are crucial for decision making at the highest level.
Therefore, from a quality assurance perspective, a rigorous testing process is necessary to ensure the stability and efficient performance of these models. This involves cutting down on biases in their development, to ensure accurate data driven decisions.
The Need for Continuous Validation of ML Models
There are various hurdles to overcome in the development of ML models. Some of the challenges that mandate the need for a QA validation team and the process of on-going validation are specified below:
- Variation in data used for model development and real-world data in production setting
ML and deep learning models are never completely accurate all the time. A critical reason behind this is the fact that data used to develop these models, and the data in the actual deployment is bound to have variations. Consider a model predicting operating conditions only for normal working conditions and one failure scenario. In production if a different failure scenario is encountered model predictions will be inaccurate, as the developed model would not have been trained on such scenarios.
- No Apriori knowledge of correct results for data validation
Traditional software testing has the benefit of an Oracle mechanism. Wherein, the program’s functioning can be evaluated against a predetermined output to evaluate its proper functioning. With regards to ML, any Oracle mechanism is possible only through constant human intervention, to ensure accurate labelled data is present for the efficient working of the models. For example, creating image tags for object identification in computer vision applications.
- Constant monitoring of deployed ML models
During the initial development stage multiple models are built. Once the most accurate model is selected, the other variants are usually discarded. However, it would be a better practice to retain the alternative models and monitor their performance separately. This helps provide future models that could guarantee higher accuracy based on new data.
- Inclusion of additional data sources and features previously not considered
As the complexity of platforms and models increases over time, organizations will look towards including additional sources of data to make ML models more robust. This requires additional efforts towards rebuilding the models and re-evaluating the revised model to ensure better accuracy and model robustness.
- Constant re-evaluation of data quality
A frequent issue when working with data is the presence of junk values, missing data and incorrect readings. When it comes to model generation and its predictive ability, a data scientist has to monitor the incoming data constantly. Doing so validates its usability for accurate predictions in real life scenarios, preventing model failure.
- Inherent human bias in model development process
ML models are developed manually keeping in mind certain assumptions regarding data distribution, with a specified development methodology. If the correct assumptions and methodologies are not taken into consideration, the models developed will be inefficient, providing biased results which can negatively impact operations and decision making capabilities.
Therefore, it is essential to ensure the presence of systems to monitor and improve upon ML models even after deployment.
Part 2 will cover elements of Black Box Testing in the context of AI and ML models.
Read more about Sasken's expertise providing efficient Digital Testing strategies.
Next Post Building a Scalable Next-Gen Transportation Solution Leveraging DevOps and Cloud










