Feb 11, 2020, 3:06:36 PM
The typical machine learning (ML) model lifecycle comprises of training and scoring pipelines. In the training pipeline multiple models are evaluated using different algorithms with the best model(s) being selected at the end. The scoring pipeline provides predictions on new data in production on these selected models. Depending on the end use case or industry application being served, these training and scoring pipelines may have to be accessed and updated with varying frequencies. This may be done monthly, daily, hourly, or even in a matter of minutes.
This post will explore some of the challenges in placing ML models in a production environment. It will also introduce few alternatives available to host different types of ML models.
Challenges in Productizing ML Models
The following are typical challenges faced while porting ML models from a development environment to a production environment: Click to Enlarge Types of ML Model Formats
Click to Enlarge Types of ML Model Formats
Once a model has been generated, it needs to be saved or exported so that it can be used for scoring and prediction. Some of the common options available are as follows:
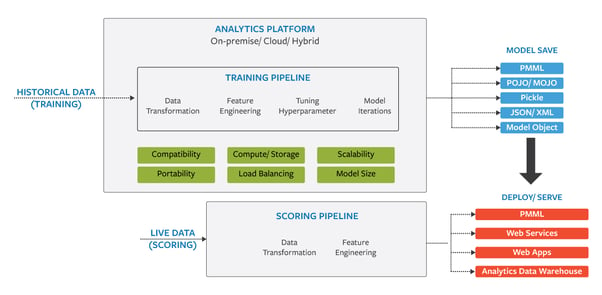 Productizing ML models – A Brief OverviewClick to Enlarge
Productizing ML models – A Brief OverviewClick to Enlarge
ML Model Deployment Options
The following are some of the viable choices for hosting ML models:
1. Pub-Sub (Publisher-Subscriber) Approach
A publisher-subscriber approach allows models to be triggered based on events or in a scheduled manner. This can be achieved by combining multiple services such as Azure Event Hubs and Azure Functions, AWS Kinesis and AWS Lambda, Apache Kafka and Spark among others.
2. Web Services
ML models can also be exposed through RESTful APIs which can be deployed as containers using Kubernetes, OpenShift, and Docker. These provide the advantage of scalability and load balancing as and when required.
3. Web Applications
Similar to the web services approach, ML models can also be exposed through web applications such as React, Dash, and Angular among others. In turn, they will call a REST API hosting the model at the backend. This approach has the advantage of proving an interactive user interface for the end users.
4. Integration with Analytics Data Mart
This is typically used in batch systems as seen in credit card approvals, managing customer churn etc. It is ideal in situations where recommendations are expected in bulk and the volume of data can be predicted.
Sasken has been engaging with its clients in deploying a wide range of solutions. This ranges from setting up Information Management Systems, implementing Big data platforms to providing data discovery services and building predictive models via Machine Learning and Deep Learning frameworks. We work with our clients across various domains such as Industrial IoT, Manufacturing, Automotive, Transportation, and Telecommunications to help address their diverse needs.
See how Sasken is helping multiple global leaders with its comprehensive expertise in IoT.









