Dec 9, 2019, 6:00:53 PM
After covering the importance of QA in the context of AI and ML models in Part 1, this post will cover the various Black box testing techniques appropriate for ML models. It will also shed some light on the best practices for their QA testing and Sasken’s unique approach.
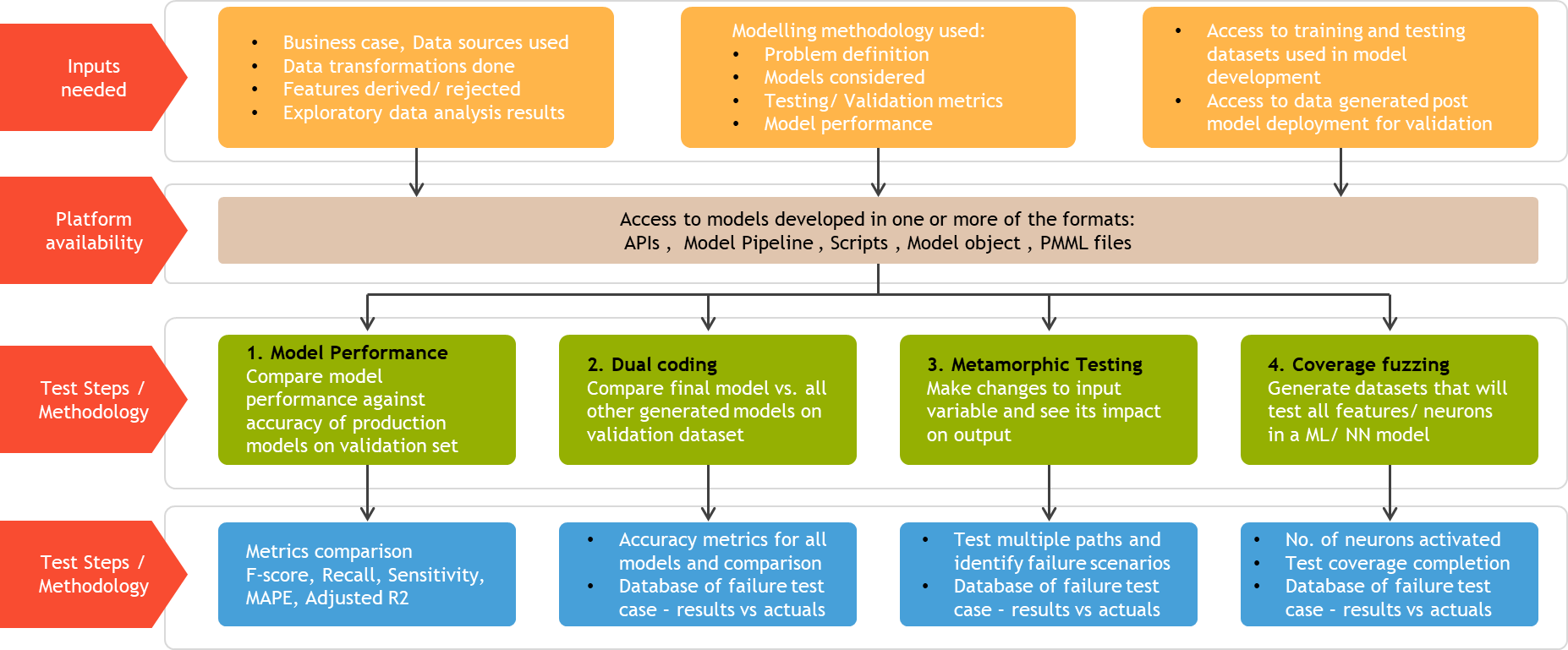
Black box Testing Techniques for ML/AI modelsBlack box testing follows a methodology, wherein the internal functional design and implementation are not known to the QA engineer. In the context of ML/ AI models, Black box testing means that aspects such as details of algorithms used, model tuning parameters, data transformation, and model features etc. are not made available to the QA engineer. This helps in providing an objective evaluation of the model, eliminates developer bias to a large extent, and exposes discrepancies in the ML/ AI application being tested. The following Black box testing techniques are adopted for QA evaluation of ML models:
In this method, we evaluate the performance of model post-deployment on test data sets and new data from production scenarios. It compares current model performance (using metrics like accuracy, recall, MAPE etc.), against accuracy at the time of deployment in an ongoing manner. Any significant differences in the metrics are highlighted and trigger a re-evaluation of the deployed model
The intent with this technique is to test all models built during the model development process, along with the final model selected for deployment. This ensures an ongoing performance evaluation of all models and gives us better insights about their behavior. For example, a data scientist might have evaluated multiple algorithms such as Random Forest, Support Vector Machine and Gradient boosted trees initially before finalizing on Random Forest for deployment. The performance of these models might improve or degrade when additional data is provided to them. In case of significant variations in results of the alternate models when compared to the finalized model, a defect is logged for further analysis by Data Scientists
Test model performance in terms of compute resources required for processing, memory required to host the model (size of model), latency in response from model execution etc. Performance degradation can also be a trigger to evaluate optimization of the existing model or development of an alternative more efficient model
This method involves data mutation to augment test data sets used for evaluating model performance and accuracy. This could involve aspects such as changing value of certain features, addition or removal of attributes, duplication of samples, removal of samples, affine transformations etc. Using this method we can potentially simulate scenarios not covered in training data, and therefore increase model stability
This technique prepares test data that ensures all features in a model or neurons in a neural network are activated and tested in turn. Based on the feedback obtained from the model, further test datasets are developed with guided test scenarios developed over time.
Best Practices for ML/ DL Model Testing
To create an effective Black box testing strategy, the following components are essential in Sasken’s approach:
Read more about Sasken's expertise in providing efficient Digital Testing strategies.








